Forskjellen mellom UMA og NUMA

Innhold

Multiprosessorer kan deles inn i tre kategorier med delt minnemodell: UMA (Uniform Memory Access), NUMA (Non-uniform Memory Access) og COMA (Cache-only Memory Access). Modellene er differensiert basert på hvordan minne- og maskinvareressursene er fordelt. I UMA-modellen deles det fysiske minnet jevnt mellom prosessorene som også har lik latens for hvert minneord mens NUMA gir variabel tilgangstid for prosessorene for å få tilgang til minnet.
Båndbredden som brukes i UMA til minnet er begrenset da den bruker en minnekontroller. Hovedmotivet med bruk av NUMA-maskiner er å forbedre den tilgjengelige båndbredden til minnet ved å bruke flere minnekontrollere.
-
- Sammenligningstabell
- Definisjon
- Viktige forskjeller
- Konklusjon
Sammenligningstabell
| Grunnlag for sammenligning | UMA | NUMA |
|---|---|---|
| grunn~~POS=TRUNC | Bruker en enkelt minnekontroller | Flere minnekontrollere |
| Type busser brukt | Enkelt, flere og tverrligger. | Tre og hierarkisk |
| Minne tilgang til tid | Lik | Endres i henhold til avstanden til mikroprosessoren. |
| Egnet for | Generelle formål og tidsdelingsapplikasjoner | Sanntids- og tidskritiske applikasjoner |
| Hastighet | Langsommere | Raskere |
| båndbredde | Begrenset | Mer enn UMA. |
Definisjon av UMA
UMA (enhetlig minnetilgang) system er en delt minnearkitektur for multiprosessorene. I denne modellen brukes og får tilgang til et enkelt minne av alle prosessorene som presenterer multiprosessorsystemet ved hjelp av samtrafikknettet. Hver prosessor har samme minnetilgangstid (latenstid) og tilgangshastighet. Den kan benytte en av enkeltbusser, flere busser eller tverrstangsbrytere. Siden det gir balansert tilgang til delt minne, er det også kjent som SMP (symmetrisk flerprosessor) systemer.
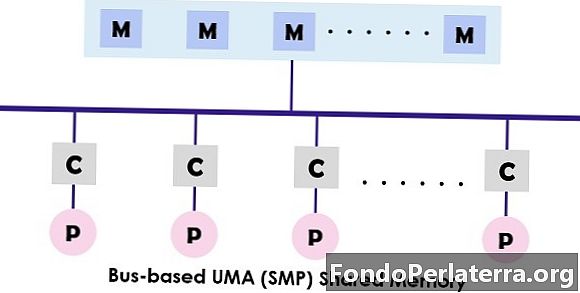
Den typiske utformingen av SMP er vist over der hver prosessor først er koblet til cachen, deretter blir cachen koblet til bussen. Endelig er bussen koblet til minnet. Denne UMA-arkitekturen reduserer striden for bussen gjennom å hente instruksjonene direkte fra den enkelte isolerte cachen. Det gir også en lik sannsynlighet for å lese og skrive til hver prosessor. De typiske eksemplene på UMA-modellen er Sun Starfire-servere, Compaq alpha-server og HP v-serien.
Definisjon av NUMA
NUMA (Ikke-enhetlig minnetilgang) er også en prosessormodell der hver prosessor er koblet til det dedikerte minnet. Imidlertid kombineres disse små delene av minnet til et enkelt adresseplass. Hovedpoenget å gruble på her er at i motsetning til UMA, er tilgangstid for minnet avhengig av avstanden der prosessoren er plassert, noe som betyr varierende minnetilgangstid. Den gir tilgang til hvilken som helst av minneplasseringene ved å bruke den fysiske adressen.
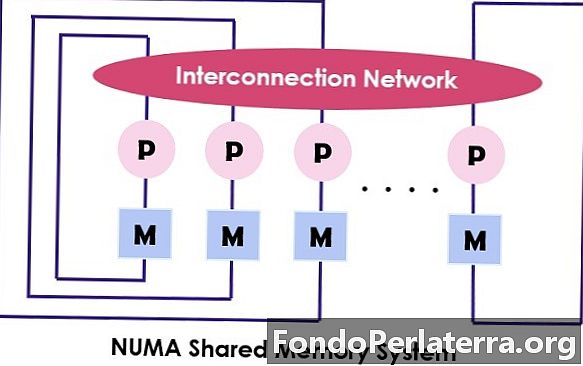
Som nevnt ovenfor er NUMA-arkitekturen ment å øke den tilgjengelige båndbredden til minnet, og som den bruker flere minnekontrollere for. Den kombinerer mange maskinkjerner til “noder”Der hver kjerne har en minnekontroller. For å få tilgang til det lokale minnet i en NUMA-maskin henter kjernen minnet som administreres av minnekontrolleren ved sin node. Mens du får tilgang til fjernminnet som håndteres av den andre minnekontrolleren, sender kjernen minneforespørselen gjennom samtrafikkkoblingene.
NUMA-arkitekturen bruker tre- og hierarkiske bussnettverk for å sammenkoble minneblokkene og prosessorene. BBN, TC-2000, SGI Origin 3000, Cray er noen av eksemplene på NUMA-arkitekturen.
- UMA-modellen (delt minne) bruker en eller to minnekontrollere. I motsetning kan NUMA ha flere minnekontrollere for å få tilgang til minnet.
- Enkelt-, flere- og tverrstangsbusser brukes i UMA-arkitektur. Motsatt bruker NUMA hierarkiske busser og nettverkstilkobling.
- I UMA er minnetilgangstiden for hver prosessor den samme, mens i NUMA endres minnetilgangstiden etter hvert som avstanden til minnet fra prosessoren endres.
- Generelle formål og tidsdelingsapplikasjoner passer for UMA-maskinene. Derimot er den aktuelle applikasjonen for NUMA sentralt og tidskritisk.
- De UMA-baserte parallelle systemene fungerer tregere enn NUMA-systemene.
- Når det gjelder båndbredde UMA, har du begrenset båndbredde. Tvert imot, NUMA har båndbredde mer enn UMA.
Konklusjon
UMA-arkitekturen gir samme totale forsinkelse for prosessorene som får tilgang til minnet. Dette er lite nyttig når det lokale minnet nås fordi forsinkelsen ville være ens. På den annen side hadde hver prosessor i NUMA sitt dedikerte minne som eliminerer latenstiden når det lokale minnet er tilgjengelig. Latensen endres etter hvert som avstanden mellom prosessoren og minnet endres (dvs. ikke-ensartet). Imidlertid har NUMA forbedret ytelsen sammenlignet med UMA-arkitektur.
 og vfork ()")




